

Chem. J. Chinese Universities ›› 2022, Vol. 43 ›› Issue (10): 20220397.doi: 10.7503/cjcu20220397
• Physical Chemistry • Previous Articles Next Articles
WU Qingying, ZHU Zhenyu, WU Jianming( ), XU Xin
), XU Xin
Received:2022-06-05
Online:2022-10-10
Published:2022-07-11
Contact:
WU Jianming
E-mail:jianmingwu@fudan.edu.cn
Supported by:CLC Number:
TrendMD:
WU Qingying, ZHU Zhenyu, WU Jianming, XU Xin. A Dataset Representativeness Metric and A Slicing Sampling Strategy for the Kennard-Stone Algorithm[J]. Chem. J. Chinese Universities, 2022, 43(10): 20220397.
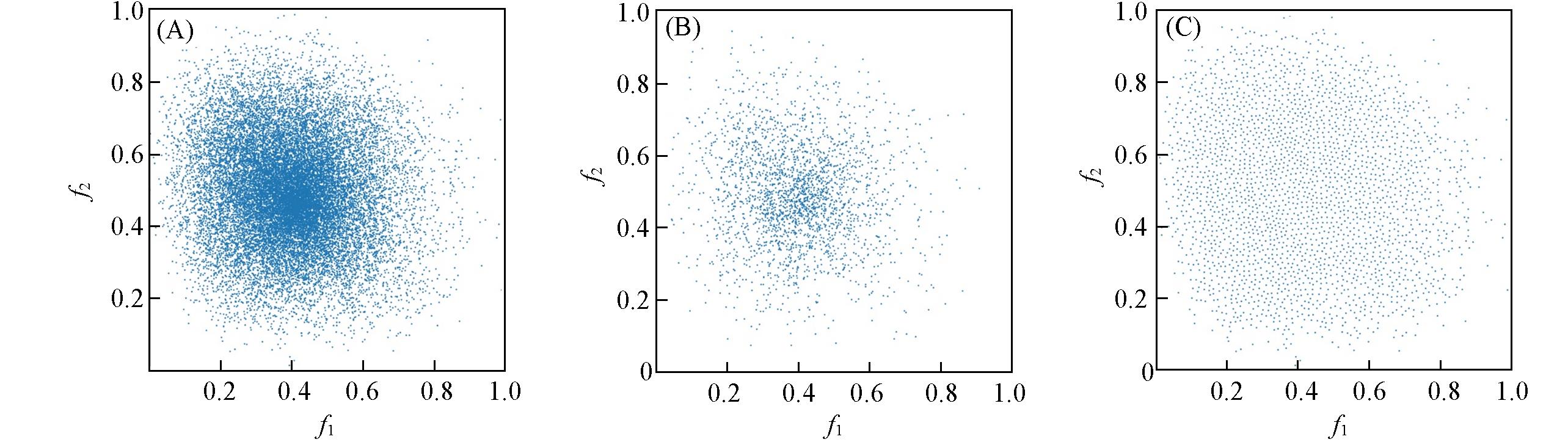
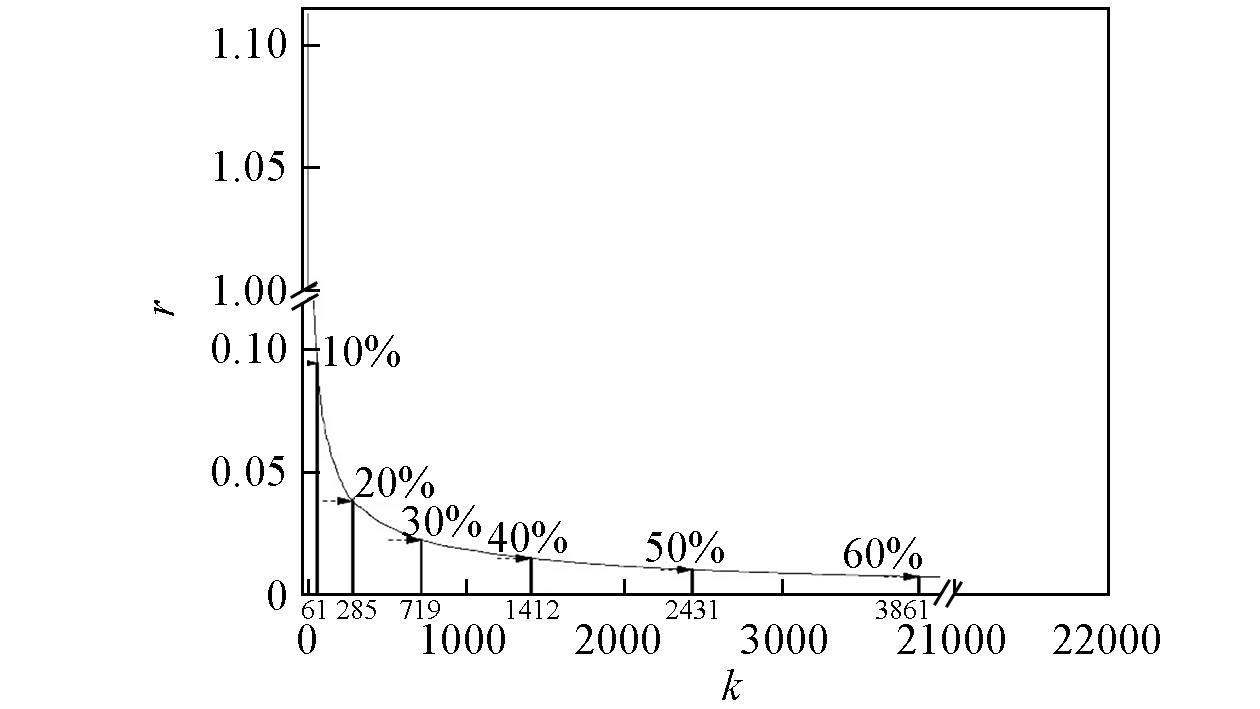
| Data | bp50 b /℃ | d4052 c /(g·mL-1) | Total d (%) |
|---|---|---|---|
| Min | 197 | 0.7818 | 13.0 |
| Max | 293 | 0.8728 | 47.0 |
| Average | 259 | 0.8446 | 30.9 |
| Nos. | 389 | 385 | 392 |
Table 1 Dataset statistics of three diesel fuel properties a
| Data | bp50 b /℃ | d4052 c /(g·mL-1) | Total d (%) |
|---|---|---|---|
| Min | 197 | 0.7818 | 13.0 |
| Max | 293 | 0.8728 | 47.0 |
| Average | 259 | 0.8446 | 30.9 |
| Nos. | 389 | 385 | 392 |
| 20% a | 50% | 80% | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Property | bp50 b | d4052 c | Total d | bp50 | d4052 | Total | bp50 | d4052 | Total |
| Sample number for calibration e | 78 | 79 | 78 | 194 | 198 | 196 | 311 | 316 | 314 |
| Sample number for prediction f | 311 | 316 | 314 | 195 | 197 | 196 | 78 | 79 | 78 |
| F?value g | 1.17 | 1.17 | 1.17 | 1.10 | 1.10 | 1.10 | 1.08 | 1.08 | 1.08 |
| PKSh | 52.9% | 51.6% | 51.8% | 78.1% | 77.6% | 77.5% | 93.8% | 93.6% | 93.5% |
| R2KSi | 0.942 | 0.992 | 0.987 | 0.964 | 0.996 | 0.989 | 0.981 | 0.997 | 0.992 |
| Psequentialh | 48.5% | 46.5% | 46.5% | 74.4% | 75.2% | 73.8% | 92.7% | 92.8% | 91.7% |
| R | 0.953 | 0.992 | 0.986 | 0.972 | 0.995 | 0.988 | 0.986 | 0.996 | 0.990 |
| Prandom?Ah | 48.2% | 44.4% | 46.6% | 73.1% | 73.8% | 73.4% | 92.2% | 92.3% | 91.5% |
| R | 0.951 | 0.991 | 0.980 | 0.956 | 0.995 | 0.987 | 0.975 | 0.997 | 0.989 |
| Prandom?Bh | 47.2% | 46.3% | 44.9% | 72.6% | 74.1% | 72.6% | 91.4% | 91.8% | 91.5% |
| R | 0.952 | 0.988 | 0.979 | 0.961 | 0.995 | 0.986 | 0.968 | 0.997 | 0.988 |
| Prandom?Ch | 46.7% | 44.9% | 48.2% | 46.0% | 73.7% | 74.1% | 73.8% | 91.9% | 91.6% |
| R | 0.945 | 0.993 | 0.989 | 0.969 | 0.995 | 0.987 | 0.978 | 0.995 | 0.989 |
Table 2 Performance tests of different slicing KS sampling strategies
| 20% a | 50% | 80% | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Property | bp50 b | d4052 c | Total d | bp50 | d4052 | Total | bp50 | d4052 | Total |
| Sample number for calibration e | 78 | 79 | 78 | 194 | 198 | 196 | 311 | 316 | 314 |
| Sample number for prediction f | 311 | 316 | 314 | 195 | 197 | 196 | 78 | 79 | 78 |
| F?value g | 1.17 | 1.17 | 1.17 | 1.10 | 1.10 | 1.10 | 1.08 | 1.08 | 1.08 |
| PKSh | 52.9% | 51.6% | 51.8% | 78.1% | 77.6% | 77.5% | 93.8% | 93.6% | 93.5% |
| R2KSi | 0.942 | 0.992 | 0.987 | 0.964 | 0.996 | 0.989 | 0.981 | 0.997 | 0.992 |
| Psequentialh | 48.5% | 46.5% | 46.5% | 74.4% | 75.2% | 73.8% | 92.7% | 92.8% | 91.7% |
| R | 0.953 | 0.992 | 0.986 | 0.972 | 0.995 | 0.988 | 0.986 | 0.996 | 0.990 |
| Prandom?Ah | 48.2% | 44.4% | 46.6% | 73.1% | 73.8% | 73.4% | 92.2% | 92.3% | 91.5% |
| R | 0.951 | 0.991 | 0.980 | 0.956 | 0.995 | 0.987 | 0.975 | 0.997 | 0.989 |
| Prandom?Bh | 47.2% | 46.3% | 44.9% | 72.6% | 74.1% | 72.6% | 91.4% | 91.8% | 91.5% |
| R | 0.952 | 0.988 | 0.979 | 0.961 | 0.995 | 0.986 | 0.968 | 0.997 | 0.988 |
| Prandom?Ch | 46.7% | 44.9% | 48.2% | 46.0% | 73.7% | 74.1% | 73.8% | 91.9% | 91.6% |
| R | 0.945 | 0.993 | 0.989 | 0.969 | 0.995 | 0.987 | 0.978 | 0.995 | 0.989 |
| 1 | Huang B., von Lilienfeld O. A., Chem. Rev., 2021, 121, 10001—10036 |
| 2 | Kennard R. W., Stone L. A., Technometrics, 1969, 11, 137—148 |
| 3 | Rajer⁃Kanduč K., Zupan J., Majcen N., Chemometr. Intell. Lab. Syst., 2003, 65, 221—229 |
| 4 | Wu W., Walczak B., Massart D. L., Heuerding S., Erni F., Last I. R., Prebble K. A., Chemometr. Intell. Lab. Syst., 1996, 33, 35—46 |
| 5 | Henle J. J., Zahrt A. F., Rose B. T., Darrow W. T., Wang Y., Denmark S. E., J. Am. Chem. Soc., 2020, 142, 11578—11592 |
| 6 | Liu J., Sun S., Tan Z., Liu Y., Spectrochim. Acta A: Mol. Biomol., 2020, 242, 118718 |
| 7 | Sun J., Wu J., Song T., Hu L. H., Shan K. L., Chen G. H., J. Phys. Chem. A, 2014, 118, 9120—9131 |
| 8 | Rodrigues A. D. P., de Gois J. S., Costa M. A. J. L., da Silva C. S., Xavier V. L., Luna A. S., Chemometr. Intell. Lab. Syst., 2020, 206, 104168 |
| 9 | Saptoro A., Tadé M. O., Vuthaluru H. B., Chem. Prod. Process. Model., 2012, 7, 13 |
| 10 | Galvão R. K. H., Araujo M. C. U., José G. E., Pontes M. J. C., Silva E. C., Saldanha T. C. B., Talanta, 2005, 67, 736—740 |
| 11 | Chen D., Cai W., Shao X., Chemometr. Intell. Lab. Syst., 2007, 87, 312—318 |
| 12 | Gani W., Limam M., J. Stat. Comput. Simul., 2016, 86, 135—148 |
| 13 | Gao T., Hu L., Jia Z., Xia T., Fang C., Li H., Hu L., Lu Y., Li H., Cluster Comput., 2019, 22, 3069—3078 |
| 14 | Li W., Fang C., Liu J., Cui J., Li H., Gao T., Li H., Hu L., Lu Y., J. Chemom., 2019, 33, e3109 |
| 15 | Li T., Fong S., Wu Y., Tallón⁃Ballesteros A. J., Kennard⁃Stone Balance Algorithm for Time⁃series Big Data Stream Mining, ICDMW, 2020, 851—858 |
| 16 | Cook R. L., ACM Trans. Graph., 1986, 5, 51—72 |
| 17 | Bridson R., Fast Poisson Disk Sampling in Arbitrary Dimensions, ACM SIGGRAPH 2007 Sketches, 2007, 22 |
| 18 | Joseph V. R., Vakayil A., Technometrics, 2022, 64, 166—176 |
| 19 | Dong Y., Xiang B., Du D., J. Chem. Inf. Model., 2017, 57, 1055—1067 |
| 20 | Bowden G. J., Maier H. R., Dandy G. C., Water Resour., 2002, 38, 2⁃1⁃2⁃11 |
| 21 | Atkinson A. C., Chemometr. Intell. Lab. Syst., 1995, 28, 35—47 |
| 22 | Clark R. D., J. Chem. Inf. Comp. Sci., 1997, 37, 1181—1188 |
| 23 | Chen W. R., Yun Y. H., Wen M., Lu H. M., Zhang Z. M., Liang Y. Z., Anal. Methods, 2016, 8, 7225—7231 |
| 24 | Sander J., Ester M., Kriegel H. P., Xu X., Data Min. Knowl. Discov., 1998, 2, 169—194 |
| 25 | Smith J. S., Isayev O., Roitberg A. E., Chem. Sci., 2017, 8, 3192—3203 |
| 26 | Shang B., Apley D. W., J. Qual. Technol., 2021, 53, 173—196 |
| 27 | Diesel Fuel Data Sets, http://www.eigenvector.com/data/SWRI/index.html |
| 28 | Haaland D. M., Thomas E. V., Anal. Chem., 1988, 60, 1193—1202 |
| 29 | Mountrakis G., Xi B., ISPRS J. Photogramm. Remote Sens., 2013, 78, 129—147 |
| [1] | ZHANG Mi, TIAN Yafeng, GAO Keli, HOU Hua, WANG Baoshan. Molecular Dynamics Simulation of the Physicochemical Properties of Trifluoromethanesulfonyl Fluoride Dielectrics [J]. Chem. J. Chinese Universities, 2022, 43(11): 20220424. |
| [2] | LIU Yang, LI Wangchang, ZHANG Zhuxia, WANG Fang, YANG Wenjing, GUO Zhen, CUI Peng. Theoretical Exploration of Noncovalent Interactions Between Sc3C2@C80 and [12]Cycloparaphenylene Nanoring [J]. Chem. J. Chinese Universities, 2022, 43(11): 20220457. |
| [3] | WANG Sijia, HOU Lu, LI Chenglong, LI Wencui, LU Anhui. Recent Advances in Synthesis and Applications of Hollow Nano-carbons [J]. Chem. J. Chinese Universities, 0, (): 20220637. |
| [4] | WANG Yuanyue, AN Suosuo, ZHENG Xuming, ZHAO Yanying. Spectroscopic and Theoretical Studies on 5-Mercapto-1,3,4-thiadiazole-2-thione Microsolvation Clusters [J]. Chem. J. Chinese Universities, 2022, 43(10): 20220354. |
| [5] | ZHANG Lingyu, ZHANG Jilong, QU Zexing. Dynamics Study of Intramolecular Vibrational Energy Redistribution in RDX Molecule [J]. Chem. J. Chinese Universities, 2022, 43(10): 20220393. |
| [6] | SHEN Qi, CHEN Haiyao, GAO Denghui, ZHAO Xi, NA Risong, LIU Jia, HUANG Xuri. A Study on the Interaction Mechanism of the Natural Product Falcarindiol with Human GABAA Receptor [J]. Chem. J. Chinese Universities, 0, (): 0. |
| [7] | CHEN Shaochen, CHENG Min, WANG Shihui, WU Jinkui, LUO Lei, XUE Xiaoyu, JI Xu, ZHANG Changchun, ZHOU Li. Transfer Learning Modeling for Predicting the Methane and Hydrogen Delivery Capacity of Metal-Organic Frameworks [J]. Chem. J. Chinese Universities, 0, (): 20220459. |
| [8] | PENG Xinzhe, GE Jiaoyang, WANG Fangli, YU Guojing, ZHOU Dong, RAN Xueqin, YANG Lei, XIE Linghai. A Theoretical Study on Tension and Reorganization Energy of Benzothiophene Grid [J]. Chem. J. Chinese Universities, 0, (): 20220313. |
| [9] | GUO Cheng, ZHANG Wei, TANG Yun. Ordered Mesoporous Materials: History, Progress and Perspective [J]. Chem. J. Chinese Universities, 2022, 43(8): 20220167. |
| [10] | TANG Qiaowei, CAI Xiaoqing, LI Jiang, ZHU Ying, WANG Lihua, TIAN Yang, FAN Chunhai, HU Jun. Synchrotron-based X-ray Microscopy for Brain Imaging [J]. Chem. J. Chinese Universities, 0, (): 20220379. |
| [11] | YANG Dan, LIU Xu, DAI Yihu, ZHU Yan, YANG Yanhui. Research Progress in Electrocatalytic CO2 Reduction Reaction over Gold Clusters [J]. Chem. J. Chinese Universities, 2022, 43(7): 20220198. |
| [12] | DAI Wei, HOU Hua, WANG Baoshan. Theoretical Investigations on the Electronic Structures and Reactivity of Heptafluoro-iso-butyronitrile Anion [J]. Chem. J. Chinese Universities, 2022, 43(6): 20220044. |
| [13] | SHI Naike, ZHANG Ya, SANSON Andrea, WANG Lei, CHEN Jun. Uniaxial Negative Thermal Expansion and Mechanism in Zn(NCN) [J]. Chem. J. Chinese Universities, 2022, 43(6): 20220124. |
| [14] | REN Nana, XUE Jie, WANG Zhifan, YAO Xiaoxia, WANG Fan. Effects of Thermodynamic Data on Combustion Characters of 1,3-Butadiene [J]. Chem. J. Chinese Universities, 2022, 43(6): 20220151. |
| [15] | GAO Zhiwei, LI Junwei, SHI Sai, FU Qiang, JIA Junru, AN Hailong. Analysis of Gating Characteristics of TRPM8 Channel Based on Molecular Dynamics [J]. Chem. J. Chinese Universities, 2022, 43(6): 20220080. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||